

NOTES: ChatGPT4's Current Ability to "Reason", & What Follows from That...
Time to actually try to create for myself an informed view on what the likely econo-societal effects of MAMLM—Modern Advanced Machine-Learning Models—will be. Wish me luck!…

Time to actually try to create for myself an informed view on what the likely econo-societal effects of MAMLM—Modern Advanced Machine-Learning Models—will be. Wish me luck!…
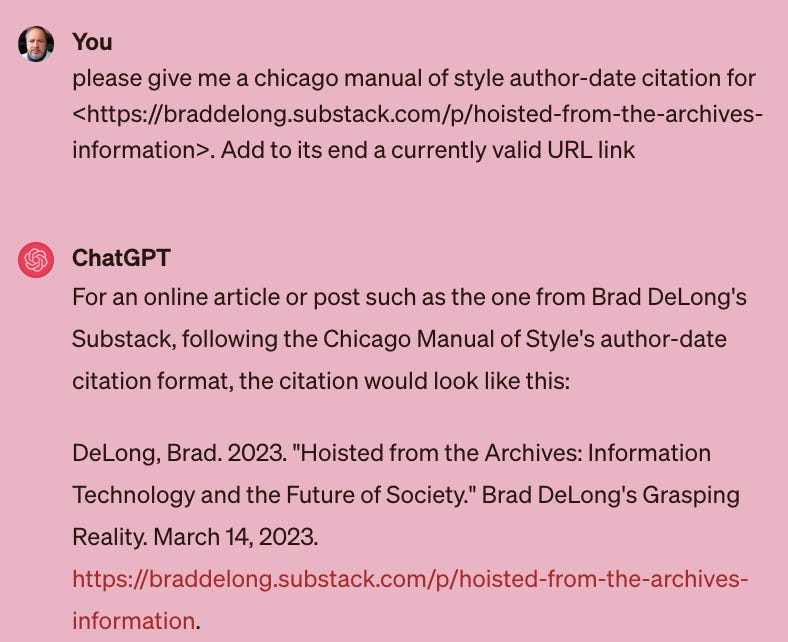
Suppose I ask ChatGPT4 for a Chicago Manual of Style citation to one of my weblog posts <https://braddelong.substack.com/p/hoisted-from-the-archives-information>: what does it produce? This:
How is it doing? Well, the weblog post is this:
HOISTED FROM THE ARCHIVES: Information Technology in the Service of Society

From 2001-09-03: How does this hold up today?...
So, on the one hand, ChatGPT4 did very good. The word is that the format is supposed to be:
Pai, Tanya. 2017. “The Squishy, Sugary History of Peeps.” Vox, April 11, 2017. http://www.vox.com/culture/2017/4/11/15209084/peeps-easter…<https://www.chicagomanualofstyle.org/tools_citationguide/citation-guide-2.html>
ChatGPT4 “identifies” and slots lastname, firstname, title, website, and URL into the format. It does all of these correctly.
On the other hand, the date on the post is March 26, 2024 (or possibly September 3, 2001).
The date on the post is not March 14, 2023.
Where does the “March 14, 2023” that ChatGPT4 thinks is the date of the post come from?
Is the piece somehow very closely related to something I published on March 14, 2023? That was my first thought. But, looking back, I do not see how it could “think” so:

So what, then, is going on? Why did it do so well on the bulk of the problem. And, given that it had the computational and syntactic capability to do so well on the problem, from where did “2023” arise to overwrite the correct “2024”? And from where did “March 14” arise to overwrite the correct “March 26”?
The answer seems to be: We do not know. Nobody has much of an idea at all.
And this is, for us, a big problem. Since we do not know how they work, we cannot project how they will scale. And since we cannot project their future capabilities and utility, we have next to no way to start imagining what their economic and societal impacts might turn out to be.
Now there are some useful things to read and watch—or at least things that I, starting from where I am with the mental panoply I have, think that I have found at least somewhat useful. (But maybe I haven’t: how would I know whether these are useful for understanding or not?) Specifically, here are the four most useful I have found:
Giulio Alessandrini, Brad Klee, & Stephen Wolfram: “What Is ChatGPT Doing … and Why Does It Work?” <https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/>.
Cosma Shalizi: “‘Attention’, ‘Transformers’, in Neural Network ‘Large Language Models’” <http://bactra.org/notebooks/nn-attention-and-transformers.html>.
Alison Gopnik: “What AI Still Doesn't Know How to Do” <https://www.wsj.com/articles/what-ai-still-doesnt-know-how-to-do-11657891316>.
Sasha Rush: “LLMs in Five Formulas” <https://www.youtube.com/watch?v=k9DnQPrfJQs>
From Alessandrini, Brad Klee, & Wolfram:
ChatGPT produces text by determining the most "reasonable continuation" based on probabilities derived from extensive textual data.
The effectiveness of ChatGPT hinges on its ability to simulate human-like text production through statistical and computational methodologies.
It is a big surprise—and discovery—that it’s possible at all for a neural net with “just” 175 billion weights to make a “reasonable model” of text humans write.
It’s interesting how little [RLHF] “poking” the “originally trained” network seems to need to get it to usefully go in particular directions.
Language is probably at a fundamental level somehow simpler than it seems, or else ChatGPT—with its ultimately straightforward neural net structure—would not have been successfully able to “capture the essence” of human language.
ChatGPT is, I think, giving us evidence of a fundamental and important piece of science: it’s suggesting that we can expect there to be major new “laws of language”—and effectively “laws of thought”—out there to discover.
From Shalizi:
Shalizi identifies the mechanism known as "attention" within neural networks, particularly in the context of transformers used in large language models, as essentially a form of kernel smoothing.
“That attention is a kind of kernel smoothing takes nothing away from the incredibly impressive engineering accomplishment of making the blessed thing work.” It is because the results are incredibly impressive that it is worth putting work into understanding these models.
Focusing on getting the next token right, recursively, is exactly what you want to focus on—and if you can find the minimal predictor that does so, you will have encoded a huge amount of information about the process.
These models are massively underidentified—which is very bad news for any hopes for parameter interpretability.
The terminology often used to describe components of neural networks and their operations (e.g., “attention”, “queries”, “keys”) does not accurately reflect the underlying mathematical processes, echoing McDermott's critique of “wishful mnemonics” in AI, suggesting a need for clearer, more accurate terminology that doesn't anthropomorphize the algorithms.
LLMs essentially operate as finite-order Markov models with their performance contingent upon the “memory” of recent inputs.
It is best to follow Alison Gopnik and conceptualize LLMs as very quirky and very experimental if advanced information retrieval systems (fuzzy JPEGs), rather than autonomous agents with comprehension or consciousness.
Precisely because these models are already so deep in the uncanny valley, it is very important to strip what is normally harmless anthropomorphization from our thoughts about them.
There are serious political (and ethical) implications of these models and their use. After all, should humanity’s way of accessing the library of human information go through a noisy sampler of the internet that has then been tuned to not offend the programmers and investors of Northern California? But engaging with the woo-woo cults on any level is really not worthwhile.
From Gopnik:
LLMs are cultural technologies like writing, printing, or the internet—tools that facilitate the transmission of knowledge and culture.
While LLMs excel at imitation, reproducing patterns observed in vast datasets, they lack the capacity for genuine innovation
Current MAMLM systems cannot grasp cause-and-effect relationships in the way humans, even very young children, can. There are huge differences between processing language and genuinely understanding the world.
We will need new norms, rules, laws, and institutions to help us wisely use MAMLM systems, just as we did for past cultural technologies. Society must innovate socially and legally as well as technologically.
A useful rant by Noah Smith from his and my Hexapodia Podcast:
Noah Smith: Even if Acemoglu and Johnson are right that the information technology revolution was massively human-substituting instead of human-complementing—which I doubt—it is simply not true that Steve Jobs knew that ahead of time. It is simply not true that the people who created this knew that they had any idea of whether or not what they were creating would substitute or complement human labor more.
That is the important part. If we think that entrepreneurs now have an accurate idea of a menu of technologies available to them and of which ones will complement humans and which ones will replace them, that is just utter hubris. Because they don't. We don't. Nobody knows. It is to worry that our technological development is on the wrong track because maybe it will produce technologies that are labor substituting in the future, when we have no good way of estimating even in partial equilibrium. Let alone in general equilibrium. We do not know what the long-run effects of these technologies on the menus of tasks that it is valuable for people to do.
And if we actually delay technological progress out of a fear of it, we are passing up opportunities to increase our human wealth, power, and flourishing that are very hard to get any other way.
We are also then believing that the future is unable to deal with its own problems. We are depriving them of opportunities to turn things to good that they might well be able to turn to good. And we are doing them on the grounds that we now know better than they what the consequences of these technologies will be, when actually we do not know what these technologies are at all, while they will… <https://braddelong.substack.com/p/podcast-hexapodia-lviii-acemoglu>
And my thoughts:
Fears that we, as a species and as a society, are not equipped for and cannot properly deal with the rapid changes and the resulting upsets in how we work, live, and think that new technology is going to bring to us are entirely rational.
Such fears are, I believe, correct.
But this has been the case for us human beings ever since 1750 or so.
There is little if any reason to think that such rational fears are materially greater now than they have been at any other time in the past two centuries or so.
Clarity of thought would be greatly increased by not calling these things “Artificial Intelligence”. How about “MAMLM”—Modern Advanced Machine-Learning Models? Or how about GPT-LLM-AML—General Purpose Transformers, Large Language Models, and Advanced Machine Learning?
These MAMLMs as the latest wave of infotech has seven aspects:
(a) “copilots” that suggest the next step;
(b) natural-language interface to databases;
(c) verbally-expressive software simulations of coaches, companions, and pets;
(d) very large-scale very high-dimension regression and classification analysis;
(e) the intersectional combination of (b) and (d) surveying the internet, in the form of ChatGPT, DALL-E, and so on;
(f) a way of separating over-optimistic investors from their wealth—rather than FILTH—”Failed in London, try Hong Kong”—we have FICTA—”Failed in Crypto, try AI”; &
(g) the latest wave of American religious or pseudo-religious enthusiasm.This infotech wave is likely to bring precarity to those who had been comfortable and privileged in their white-collar status. But governments can manage precarity.
The principal block to precarity’s management has, since the coming of the Neoliberal Order around 1980, been a refusal of the comfortable to take it seriously. As is often the case, the middle classes and the professional classes did not see themselves as having anything in common with the working classes.
That may change as MAMLMs bring a step rise in precarity to white-collar lives: we may see more of a recognition that those who lose out from technology and have a hard time keeping their place are not merely slackers and moochers.
GPTs and LLMs: These models, particularly GPTs, exhibit traits of general-purpose technologies, suggesting significant economic and social implications.
Guesses are that around 19% of the U.S. workforce could have at least 50% of their work tasks affected by the introduction of LLMs in the next fifteen years—not large-scale replacement of humans by AIs, but large-scale transformations of jobs.
There is no reason to think that MAMLM will put humans in the position of horses in the 1920s—no reason to think this is “Peak Horse” for monkeys.
The stakes are potentially large in figuring out how to make MAMLM more labor-complementing than labor-substituting.
References:
Acemoglu, Daron, & Simon Johnson. 2023. Power and Progress: Our Thousand-Year Struggle Over Technology and Prosperity. New York; Hachette Book Group. <https://archive.org/details/daron-acemoglu-simon-johnson-power-and-progress-our-thousand-year-struggle-over->
Alessandrini, Giulio; Klee, Brad; & Wolfram, Stephen. 2023. “What Is ChatGPT Doing… & Why Does It Work?” February 14, 2023. <https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/>.
DeLong, J. Bradford. 2023. “Hoisted from the Archives: Information Technology and the Future of Society”. Brad DeLong's Grasping Reality. March 14, 2023. <https://braddelong.substack.com/p/hoisted-from-the-archives-information>.
DeLong, J. Bradford. 2023. “Unproductive & Productive Tech Bubbles: BRIEFLY NOTED: For 2023-03-14 Tu”. Brad DeLong's Grasping Reality. March 14, 2023. <https://braddelong.substack.com/p/unproductive-and-productive-tech>.
DeLong, J. Bradford, & Noah Smith. 2024. “Acemoglu & Johnson Should Have Written About Technologies as Labor-Complementing or Labor-Substituting”. Hexapodia Podcast. LVIII, March 19. <https://braddelong.substack.com/p/podcast-hexapodia-lviii-acemoglu>.
DeLong, J. Bradford; & Noah Smith. 2023. “We Cannot Tell in Advance Which Technologies Are Labor-Augmenting & Which Are Labor-Replacing”. Hexapodia Podcast. XLIX, July 7. <https://braddelong.substack.com/p/hexapodia-xlix-we-cannot-tell-in>
Dubber, Markus D.; Frank Pasquale; & Sunit Das, eds. 2020. The Oxford Handbook of Ethics of AI. Oxford: Oxford University Press. <https://academic.oup.com/edited-volume/34772>
Gopnik, Alison. 2022. “What AI Still Doesn't Know How to Do”. Wall Street Journal. July 15. <https://www.wsj.com/articles/what-ai-still-doesnt-know-how-to-do-11657891316>.
Korinek, Anton. 2023. “Language Models and Cognitive Automation for Economic Research'“. CEPR. February 20. <https://cepr.org/publications/dp17923>.
OECD. 2022. AI and the Future of Skills, Volume 1: Capabilities and Assessments. Paris: OECD Publishing. <https://www.oecd-ilibrary.org/education/ai-and-the-future-of-skills-volume-1_5ee71f34-en>
OECD. 2023. AI and the Future of Skills, Volume 2: Methods for Evaluating AI Capabilities. Paris: OECD Publishing. <https://www.oecd-ilibrary.org/education/ai-and-the-future-of-skills-volume-2_a9fe53cb-en>
Rotman, David. 2023. “How ChatGPT will revolutionize the economy”. MIT Technology Review. March 25. <https://www.technologyreview.com/2023/03/25/1070275/chatgpt-revolutionize-economy-decide-what-looks-like/>.
Rush, Sasha. 2024. “LLMs in Five Formulas”. Harvard Data Science Initiative. March 12. <https://www.youtube.com/watch?v=k9DnQPrfJQs>
Shalizi, Cosma. 2024. “‘Attention’, ‘Transformers’, in Neural Network ‘Large Language Models’”. Bactra Notebooks. March 4. <http://bactra.org/notebooks/nn-attention-and-transformers.html>.
Some very interesting observations.
What should we call this technology? IMO, we should use easy to recall names, not acrobyms. Just as rule based models with coded knowledge were called "expert systems", or rules created using data "decision trees", I would use the term "language systems" or "language Model".
IMO, these language models are replicating Kahneman's "thinking fast" (System 1). System 1 allows fluid verbiage that flows without thinking. For example, when I used to mimic Robin Leech's verbiage on the lifestyles of the rich, I had no idea what I was going to say next, I just let the words flow. In a similar vein, for those with dual or more languages, stress may revert the structure of spoken English (2nd language) to that of the native language, that may be more deeply embedded in the cortex.
Idk about "laws of Thought", but I have been playing with testing Chomsky's innate grammar with ChatGPT (3.5) and I think it may invalidate it. Our language acquisition may be purely mimicry, ie learning by example, just like langyage models.
Will language models change society? Historically, we built systems and machines to carefully reproduce a consistent result. From draught animales turning a wheel, to powered machinery weaving cloth, to factory systems turning out exact replicas of objects. These muscle substitutes hugely enhanced our societal productivity. Computers when used in association with these tools, like controlling robots similarly do so. But computers used a "bicycles for the mind" don't just speed teh journey from A to B, but allow exploration and taling mental journeys far further afield. This is why computer software like spreadsheets, word processors, and so forth, do not reduce employment, but expand it. It is a mental equivalent of Northcote's Law - mental work will expand given the allowed time to complete it.
Language models have, however, a flaw, that you demonstrate at teh outset. They are not like software to control machines to replicate outputs, but instead, just like probabilistiv Markov models. The output will vary with small changes in input (prompts). This suggests to me that unless this can be fixed, language models are best used where accuracy is not needed. For example, software algorithms must be accurate and not break, and this is tested with QA methods, especially to detect "corner cases". (Expert Systems and Decsion Trees are "brittle" when unexpected data "broke" the rule structure".) So language models work well to create drafts of text, images based on similar approaches, and other creative applications where accuracy is not important. Where they fail is where accuracy is needed, such as your citation builder example.
Just as software engineers end up in cycles of reiterating code to meet the non-expert verbal instructions - "That is not exactly what I meant. can you do [X]", language models need to be able to handle recursion of prompt instructions. But just as the complexity often results in "I could do this faster than repeated instructions to subordinates", so I think language models will not be productivity enhancing without help. Can they be induced to attempt Kahneman's "thinking slow"? Idk. What I do think is possible is that they be integrated with existing software that does do the task effectively. In your example, there are many citation builders available. Some can guess at teh correct citation and output directly from the database of content using just the title. If that fails, then inputting details into the input fields solves the problem. Integrating a language model with an existing citation builder would likely produce accurate output and would be productivity enhancing. If you need real math done, integrate with Mathematica to build the model and test inputs. Once a correct version is built, "fix" that model for future requests, rather than teh language model building it from scratch each session. Similarly, using texts, go through teh selection process of texts to use with teh language model, and fix those texts in a database, so that requests of information from texts always uses those texts alone. It should not try to build a language model on those texts, but extract exact pieces from those texts to build a precis, or build an argument, "for and against" an assertion to be tested. Just as computers and software do not reinvent basic operations on numbers, so language models should operate using existing algorithms where accurate results are needed, and used their creative, sloppy, responses to convert the output to human language if needed.
"ChatGPT4 “identifies” and slots lastname, firstname, title, website, and URL into the format. It does all of these correctly."
Its subtitle is "Information Technology and the Future of Society." Your original subtitle is "Information Technology in the Service of Society"