



Nvidia’s Moment
& þe Three Bid Questions We Need Answers to to Understand It, & þe Impossibility of Answering Þem Right Now...

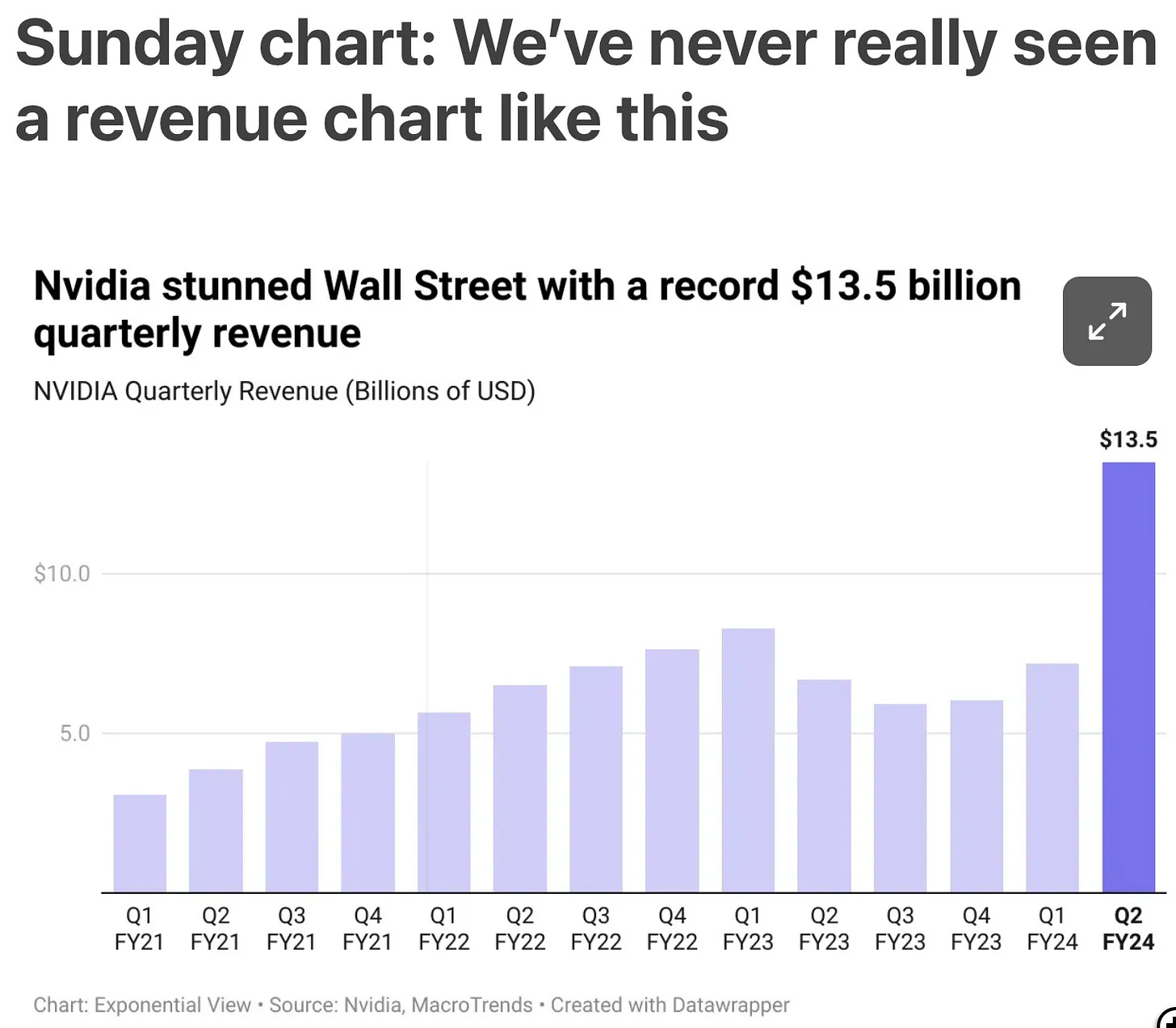
Up through the beginning of Nvidia's fiscal year 2023, revenue had grown 2.5-fold in two years, driven by the crypto bubble and the usefulness of its chips designed for graphics as the best processors on which to run costly, dissipative, and societal-destructive crypto mining.
Then came the crypto winter. Not only were crypto firms no longer buying Nvidia-designed chips, but crypto firms were ditching their Nvidia-designed chips and selling them back into the graphics market. It was turning out that the crypto bubble had not boosted demand for Nvidia-designed chips, but simply moved demand forward in time by perhaps a year and a half.
By late in its fiscal year 2023 Nvidia looked to be in real trouble—never mind that its chip designers were best-in-class, and that its Cuda framework was clearly the best way for humans to figure out how to get the stone to actually think.
And then came Midjourney and Chat-GPT…
The big questions now are three:
How fast can (or maybe will—lot of short-run monopoly power here) Nvidia (and TSMC) ramp up production of Nvidia-designed chips in order to meet demand?
Can competitors who lack CUDA nevertheless be good enough either to provide an alternative for people pushing modern ML forward?
How large will the modern ML market segment turn out to be?
I do not have any answers to these questions. And, as Friedrich von Hayek pointed out long ago, they are not the kinds of questions that we have enough information for anyone to answer. We have to let the market grope forward to solutions.
But we do know the bull case for NVIDIA and its ecosystem. Here is Ben Thompson summarizing NVIDIA CEO Jason Huang from last May:
Ben Thompson: Nvidia Earnings, Jensen Huang’s Defense, Training Versus Inference: ‘“The CPU[‘s] ability to scale in performance has ended and we need a new approach. Accelerated computing is full stack….” This is correct…. [To] run one job across multiple GPUs… means abstracting complexity up into the software…. “It’s a data-center scale problem….” This is the hardware manifestation of the previous point…. “Accelerated computing is… domain-specific… computational biology, and… computational fluid dynamics are fundamentally different….” This is the software manifestation of the same point: writing parallizable software is very difficult, and… Nvidia has already done a lot of the work…. “After three decades, we realize now that we’re at a tipping point….” You need a virtuous cycle between developers and end users, and it’s a bit of a chicken-and-egg problem to get started. Huang argues Nvidia has already accomplished that, and I agree with him that this is a big deal….
Huang then gave the example of how much it would cost to train a large language model with CPUs… $10 million dollars for 960 CPU servers consuming 11 GWh for 1 large language model… $400k… [2 GPU servers] 0.13 GWh…. The question, though, is just how many of those single-threaded loads that run on CPUs today can actually be parallelized…. Everyone is annoyed at their Nvidia dependency when it comes to GPUs…. Huang’s argument is that given the importance of software in effectively leveraging those GPUs, it is worth the cost to be a part of the same ecosystem as everyone else, because you will benefit from more improvements instead of having to make them all yourself….
Huang’s arguments are good ones, which is why I thought it was worth laying them all out; the question, though, is just how many loads look like LLM training?… Nvidia is very fortunate that that the generative AI moment happened now, when its chips are clearly superior…. The number of CUDA developers and applications built on Nvidia frameworks are exploding…. There are real skills and models and frameworks being developed now that, I suspect, are more differentiated than… the operating system for Sun Microsystems was…. Long-term differentiation in tech is always rooted in software and ecosystems, even if long-term value-capture has often been rooted in hardware; what makes Nvidia so compelling is that they, like Apple, combine both…
Matrix multiplication and inversion will never go out of style. Since the physicists tell us that everything is locally linear, at some point linear algebra will come crawling out of the snarls and tangles. The integer banging as in crypto comes and goes, but there big matrices needing heavy processing will always be with us.
Computer hardware seems to come in cycles. There's some great new idea, let's say hardware hashing support, floating point arithmetic, video compression / decompression or vector computation, and there is suddenly a growing market for a specialized piece of hardware to be hooked up to one's CPU. I remember when Mercury made vector processing boards back when CAT scanners and petroleum geologists needed to number crunch.
In the next part of the cycle, those special operations become CPU features with a new set of instructions and instruction prefixes and perhaps a new mode added to the repertoire. You have to move way down the CPU ladder to find a processor without a few CRC instructions or built in floating point nowadays. Most modern CPUs have a good chunk of graphics processor on chip or chip adjacent, but NVidia is still way out ahead.
I think the next barrier is going to be good enough. Already, LLM companies are offering ways to perturb their existing LLM with a customer's data to produce a specialized LLM with much less computing than building one from scratch. Right now, this is still beyond the capability of a typical laptop or desktop, but there's no reason this will be true in, let's say, five years. For one thing, there will be more precomputed starting state LLMs and, for another, the algorithms will improve. Meanwhile, baseline CPUs will just keep getting better and faster. (I'd be surprised if no one at Apple is working on this for some future version of Spotlight.)
There will still be a big market for high end processing boards, but it will no longer be driven by LLMs as it is now. I can't predict the next frontier, but it's a fair guess that it will involve matrices.