



The Onrushing Wave of the Infotech Revolution
An early DRAFT of a piece I did for a 2024 look-ahead for Nikkei in Japan...

An early DRAFT of a piece I did for a 2024 look-ahead for Nikkei in Japan...
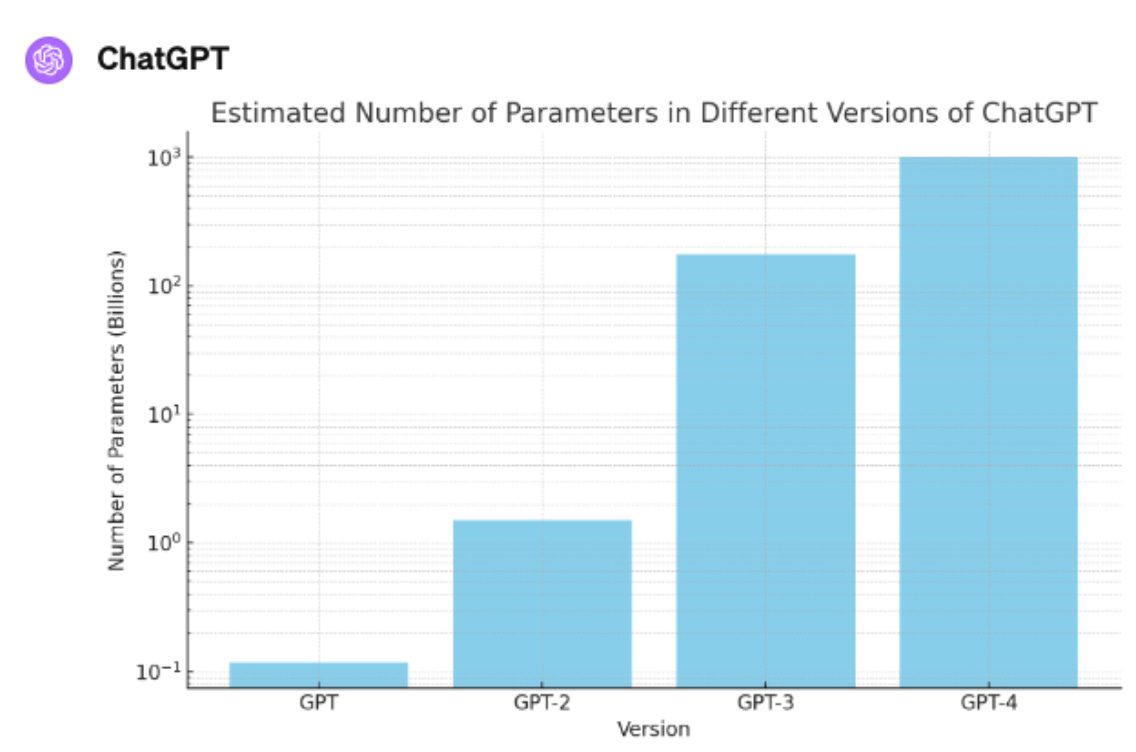
Nine months ago New York Times columnist Ezra Klein wrote, with respect to the onrushing approach of the latest revolution in information technology in the form of large-scale neural-network machine-learning model systems like OpenAI’s ChatGPT4:
Ezra Klein: 2023. “Chatbots, Artificial Intelligence, and the Future of Weirdness.” The New York Times, March 12. <https://www.nytimes.com/2023/03/12/opinion/chatbots-artificial-intelligence-future-weirdness.html>: ‘Sundar Pichai… of Google … [is] not… known for overstatement… [but] said, “A.I. is probably the most important thing humanity has ever worked on. I think of it as something more profound than electricity or fire”…. Perhaps the developers will hit a wall they do not expect. But what if they don’t?… There is a natural pace to human deliberation. A lot breaks when we are denied the luxury of time…. We can plan for what we can predict (though it is telling that, for the most part, we haven’t). What’s coming will be weirder…. If we had eons to adjust, perhaps we could do so cleanly. But we do not…
The fear is that we, as a species and as a society, are not equipped for and cannot properly deal with the rapid changes and the resulting upsets in how we work, live, and think that new technology is going to bring to us. Thus we are not prepared to handle it well, and there is the possibility that it may turn out to trigger some form of societal or human catastrophe.
This fear on Ezra Klein’s part is entirely rational. And it is, I believe, correct.
But what the extremely intelligent Ezra Klein misses, I believe, is that this has been the case for us human beings ever since 1750 or so. The Kingdom of France in the late 1700s was the most powerful and one of the richest, most secure, and productively organized in the world. The landowners, courtiers, bureaucrats, and military commanders who made up its aristocracy sat secure in their seats. They had no idea that the then-ongoing shifts in technology and society involved in the transition from feudal-agrarian to contractual-commercial society would lead to the political upheaval that was the great French Revolution of 1789–1804. And the pace of technological change then was much less than the one we have gotten accustomed to since at least the days of our great-grandparents.
You in Japan know this very well. The régime established under Tokugawa Ieyasu in common year 1603 attempted to hold back the coming of economic and societal change to the extent possible, and succeeded to a remarkable degree until 1854. But the consequence was that every generation since the people of Japan have lived in a new and different economy underpinned by different and much more productive technologies—a doubling of the typical citizen of Japan’s ability to productively produce via manipulation nature and coöperating with other humans each generation. And each generation since 1854 has seen Japan’s leaders and citizens try to rework the pattern of society and economy in order to benefit from greater capabilities and higher productivity.
The road for Japan has been, at times, very rough. The worst stretch of all—for the people of Japan and of the territories its government sought to include in an empire—came in the later stages of the stretch over 1895–1945, when Japan suffered from a bad case of the imperialism-nationalism mind virus it caught from the Western European empires. But as of now every observer must be more satisfied with the current configuration of Japan’s economy and society than with any previous one. If the citizens and leaders of Japan have not managed to take full advantage of the opportunities to positively rework economies and societies opened up by technological advance, they have managed to take very good advantage of the opportunities.
Thus the task of productively managing the onrushing approach of the latest revolution in information technology and using our enhanced capabilities for good should not be beyond us: we know how to do this—as long as the pace of technological advance is not about to become vastly greater than it has been over past generations, and as long as our systems of adaptation remain as strong as they have been. So those are our two questions that we must answer.
Is the overall pace of technological change arising from the latest revolution in information technology vastly greater than the pace of change in the past? My judgment, at this point, is that the answer is almost surely “no”. Economic statistics and forecasts tell us that the pace of technological change over the past decade and into the future are, if anything, somewhat slower than Japan has experienced on average since 1853. And an examination of the pieces of the onrushing latest wave of information-technology revolution reinforces that judgment. I count seven aspects in the latest wave:
“Copilots” that suggest the next step.
Natural-language interface to databases.
Verbally-expressive software simulations of coaches, companions, and pets.
Very large-scale very high-dimension regression and classification analysis.
The intersectional combination of (2) and (4) surveying the internet, in the form of ChatGPT, DALL-E, and so on.
A way of separating over-optimistic investors from their wealth.
The latest wave of American religious enthusiasm.
The first of these is likely to be the biggest. Indeed, we can already see how computer programmers and intensive users will benefit from it as it is already being implemented in the form of Github Copilot. Tools that sit at your side and suggest the next operation you will wish to perform, which you implement by pressing the key will provide another upward leap in programmer and intensive user capabilities akin to those generated by earlier frameworks and abstraction layers. Figure that over the next two decades we will obtain a doubling of productivity for the 5% of the workforce that most intensively use computers—that is an 0.25%-point increase in the annual rate of economy-wide technological progress.
The second is likely to be of an equal magnitude. We communicate, learn, and inform via natural language. ChatGPT4 and its ilk are now good enough to simulate a conversation to the extent that they will soon be able to reliably populate databases in response to human input and draw from databases in order to generate useful language-structured output for humans. These interactions will not be conversations—while there is a human mind on one side, there is no mind at all on the other. But with humans designing the databases backing up the ChatBots, these interactions will be a vast improvement over what we have now.
Good enough as a natural-language front-end to databases; almost good enough as an interlocutor…
The fact that the conversations will be “good enough” will bring transformations in human society. We have long talked to our pets and our imaginary friends. We have all benefited from interaction and feedback from our coaches. But, in the future, for the first time, our pets and our imaginary friends will answer us back—we will not have to imagine what they would say. And, for the first time, a first-class coach will be available to everyone for free. This may not be for our unalloyed good. But our negative experiences with the social-media drawbacks of corporations incentivized to capture our attention simply to show us ads should teach us lessons that will allow us to inoculate ourselves.
By the time we reach the fourth, we have benefits that, while still substantial, are smaller. Our ability to classify, measure, and predict is already great. Yes, further improvements in machine learning will allow Apple Computer to not just label that a picture contains a dog but correctly label which of my dogs is in which picture, making searching my photo database somewhat easier. And this capability—and all the other better fine-tuning of classification, measurement, and prediction—will enrich my life. But this is at the margin.
But at this point we have, I think, reached the end of the useful contributions the next information-technology wave has to offer us. Language- and image-generation models trained on the entire internet have made a huge public-relations splash, but they are unreliable as sources of information and insight, for what you get out of them is close to the energy you have to put into them to fine-tune them for accuracy. The wholesale move into “AI” of the speculators and projectors who two years ago were telling us that crypto would carry us to the moon is likely to be a net minus for society. And the worries that we are building our software-robot overlords seems to me to be yet another version of California Spiritualism, which is itself a descendent of American patterns of inventive religious thought we have seen regularly since the First Great Awakening of Jonathan Edwards and George Whitefield in New England in the 1730s.
However, add all these up, and they promise to be a significant plus for humanity. We can guesstimate that the next wave of information technology will drive a boost to the rate of advanced-country technological progress in the range of 0.5%-points to 1.0%-points per year over the next 20 years. That will be very welcome, especially as we must somewhere find the resources to begin cushioning and compensating people for the losses that will be generated by global warming. But that is not enough to make the pace of change unmanageably fast—except to the extent that the pace of change has already been, since 1854, unmanageably fast.
Are there big minuses? The big fear is that this will be the first time that technological change threatens to disemploy well-paid white-collar workers rather than blue-collar workers, and that will cause much more societal upset than did previous waves. I, however, remember that the Great Depression of the 1930s taught middle classes in industrial countries all around the globe that their prosperity was precarious, and that they had powerful interests in common with lower-paid working classes. And I remember that the generation that followed was one of enormous relative industrial-country societal harmony.
Thus while I agree that this infotech wave is likely to bring some precarity to those who had been comfortable and privileged in their white-collar status, governments can manage precarity. The principal block to its management has, since the coming of the Neoliberal Order around 1980, a refusal of the comfortable to take it seriously. So perhaps there is an upside here, once we take this feedback into account.
References:
Klein, Ezra: 2023. “Chatbots, Artificial Intelligence, and the Future of Weirdness.” The New York Times, March 12. <https://www.nytimes.com/2023/03/12/opinion/chatbots-artificial-intelligence-future-weirdness.html>
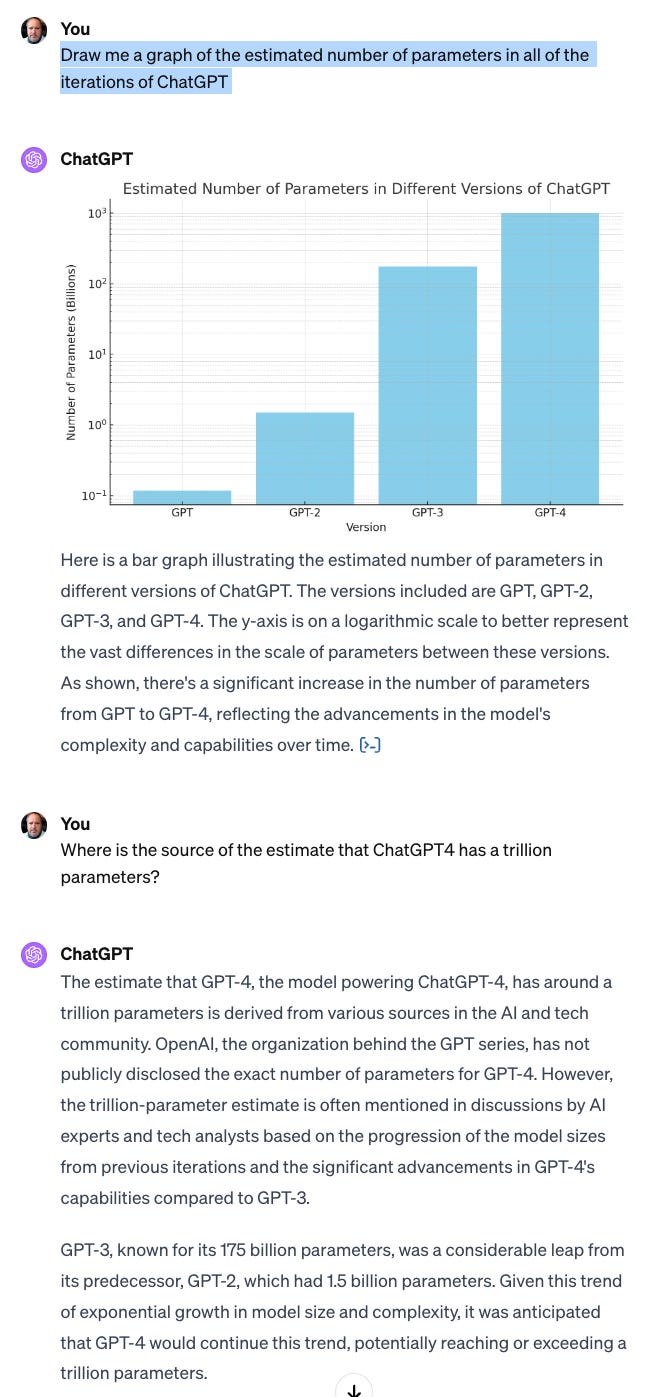
ChatGPT labelled that graph 10^3 (Billions) instead of just 10^12, obliging it to start at 10^-1. Did it copy that tic from its source, I wonder?
Geoff Hinton is fond of saying that back in the 80's AI researchers were taking a sui generis approach to each problem domain. He and his colleagues were running around saying that their neural net approach was the only approach needed, it could replace all the others. But at the time, it didn't work. There were only two problems: they didn't have enough data, and they didn't have enough compute. That's not surprising if you need a trillion parameters in practical situations.
The current performance of LLMs is due to remedying these two defects. So far, my experience with co-piloting is underwhelming; they slow me down by nearly as much as they speed me up. Are improvements in the intelligence part of AI extrapolated from this sort of exponential graph? Training a very large LLM is already very expensive; will the next iteration be *exponentially* more expensive?
For example, title of chapter 2 in that Fogel Book: Technological Change, Cultural Transformation and Political Crises. You've probably covered some of it in Slouching. But more could be said, too, about things that Fogel didn't see coming etc. Roughly 25 years have gone by since.